In this post, I’m talking about my journey to create a chatbot that knows about Persian writers and poets. It was a fun project, showing the good and tough parts of using Big Language Models (LLMs). You can check out the app here: Persian Poets.
ChatGPT and other LLMs are catching a lot of attention, especially from businesses. Everyone, from the CEO to team leaders, is excited about how ChatGPT can help their customers. I’ll quickly review how I made this model, including the time and money it took. I plan to share the code for everyone to use when I can find the time (which usually never happens).
Persian culture is deeply rooted in the art of poetry. Though poets like Rumi and Hafiz are familiar in the West, many remain lesser known. For this project, I gathered information on these poets from Wikipedia and fed it into my model (full list here). By the end, you’ll be able to ask, “Who is Rudaki?” and receive an answer.
If you’re more business-minded and don’t care about the tech stuff, skip to the “It’s not that hard” section. I clock my work in ‘Pomodoro’ units, each about 25 to 30 minutes long, breaks included. In the sections that follow, I’ll show you how I made this happen over three weekends, this write-up included.
Note from Hamid R. Darabi: I strictly forbid any AI model from using this blog post for training purposes in any way. Violations will be treated as copyright infringement and punished by law.Disclaimer: Opinions are my own and not the views of my employer. I frequently update my articles. This is version 1.0 of this article.

Preparing the Dataset
I needed a dataset that was easy to use and had the following features:
- It’s open source with a lenient license,
- It’s easy to handle,
- It offers something useful to the user, and
- It’s unique.
After brainstorming with my wife, I chose to use the list of Persian poets and authors from Wikipedia to train my language model. You can find the complete list here. Here’s how I planned to download this dataset and turn it into something the model could use:
- I started by getting the list of links from the main page and saved it to a CSV file. I used ChatGPT to write the Python code for this and ran it. (Took about half an hour).
- Then I manually removed the irrelevant links. It was easier to spot these by simply looking at them rather than writing code to do it. This left me with 628 articles to download.
- I wrote code to download the core content from each page and turn it into a JSON file with the name and title of each section. Along with the previous step, this took about an hour.
- I turned the JSON files into a set of question-and-answer files. This is where ChatGPT really came in handy! I gave it instructions, and it wrote the code that sends each file to the OpenAI API. This means I used AI to write AI – pretty neat! (Took an hour).
In the end, my dataset had around 41,169 question-and-answer pairs. It’s not that big, and the quality of some questions is a bit iffy, but that’s a good starting point.
Model Training
The first step in fine-tuning models is to pick the base model you want to use. BLOOMs are a range of models released by a group of scientists, and they fit my needs perfectly. To make sure the training went smoothly, I followed these steps:
- I began with a modest model (bigscience/bloom-560m) to create and test my pipeline. I borrowed much of the code from the official guide on fine-tuning models using the HuggingFace library. This model is small enough to run locally on your CPU. (Took about half an hour)
- I made my first mistake here! I used the PyTorch Dataset format to transform my dataset into a format the model could use. This is a simple class for automating dataset creation. But, I overlooked the fact that I wasn’t using PyTorch for training; I was using HuggingFace. I rewrote the code after I figured out the issue (It took an hour to fix).
- Next, I was ready to scale up the model. I chose bigscience/bloom-7b1, a model with 7 billion parameters, as my main model and trained it on my dataset. It took half an hour to prepare the machine and another 4 hours and 2 minutes to train for 3 epochs on an A40 NVIDIA GPU. This cost me about $4.1 in total. (Took half an hour)
- Here’s where I made my second mistake! I planned to run the model on a CPU machine for inference. But, I discovered that the 7B parameter model was too big to fit on 32GB of memory. So, I had to choose a smaller model for deployment. I’ll talk more about that in the next section.
- I trained a different model with 3B parameters (bigscience/bloom-3b). Since I had destroyed the previous machine, I needed to spend another half an hour setting up a new one. The training took around 2 hours and 32 minutes for 4 epochs and cost about $1.1. (Took half an hour)
In the following section, I’ll discuss the hurdles I faced when deploying the model.
Model Deployment
Running the model for inference is the most expensive part of the process. Given my low traffic, I considered these options:
- AWS Lambda: This could be cost-effective, especially with the free tier. But due to Lambda’s memory constraints, it wasn’t a practical choice. I also thought about loading the model into a Docker image on AWS ECS, but the image size limits fell short of my needs. Since I was trying to save time, I didn’t look into other complex solutions.
- Dedicated GPU server: This was too costly. A g4ad.2xlarge machine would set me back about $390 a month.
- Elastic Inference (EI): I wasn’t sure if my model could fit into the 8GB machine that AWS provides. If anyone knows of a solution beyond techniques like 4-bit precision and model distillation, please share.
- In the end, I decided to use a machine with a dedicated CPU. It’s expensive, inefficient, and most importantly, slow. I went with an r6a.xlarge machine, which costs about $164 monthly.
Deploying the model wasn’t too hard. I had ChatGPT write a REST API backend using Flask, and I made a few small changes. I ran it with Gunicorn. Adding a reverse cache server like Nginx could be very valuable. I didn’t do that to save time, but it could help with another issue I’ll describe later. (Took an hour)
Front End
The final step was to create a nice front end for my app. I wanted users to engage with my app through a pleasant website, not by sending REST requests via Postman. (If you know what I mean).
I initially thought of creating a sleek React app that links to my REST backend. But I wanted to launch it on my WordPress blog. So, I tried a JavaScript browser-based solution. Sadly, it didn’t work out.
The issue was that my backend was using HTTP (an insecure protocol), but my WordPress was set up for HTTPS. This led to security errors, making it an unworkable solution. I spent about an hour and a half trying to fix it, to no avail. (Took 1.5 hours)
Chatting with ChatGPT proved enlightening at this stage. It suggested creating a middleware using PHP. This would take the POST request from my HTML form, send it to the backend, parse the results, and display them on the front end. I’m familiar with PHP, so I quickly corrected some errors in ChatGPT’s version of the solution. (Took less than an hour)
After eight and a half hours, my complete application was ready and can be accessed here: Persian Poets.
Does it work?
Short answer: Yes, up to a point!
Long answer: Testing large language models is a complex endeavor. How do you measure a model’s response? I used a straightforward zero-shot evaluation method as follows:
- I crafted a small dataset of four types of questions:
- Direct questions from the dataset, like “Who was Abu Sa’id Abu’l-Khayr?”
- Rephrased versions of dataset questions, like “Can you tell me about Abu Sa’id Abu’l-Khayr?”
- Questions requiring reasoning and judgment related to the dataset, such as “In which century did Ferdowsi live and write?”
- Questions similar to those in the dataset but not included in it, such as “Where was Hamid R. Darabi born?”
- I contrasted the outputs of five models: ChatGPT4, Trained 3B, Trained 7B, UnTrained 3B, and UnTrained 7B.
- I utilized the following codes to summarize the results: (N) no output, (G) nonsensical answer, (M) meaningful but incorrect answer, (P) perfect answer.
The results are summarized in the table below.
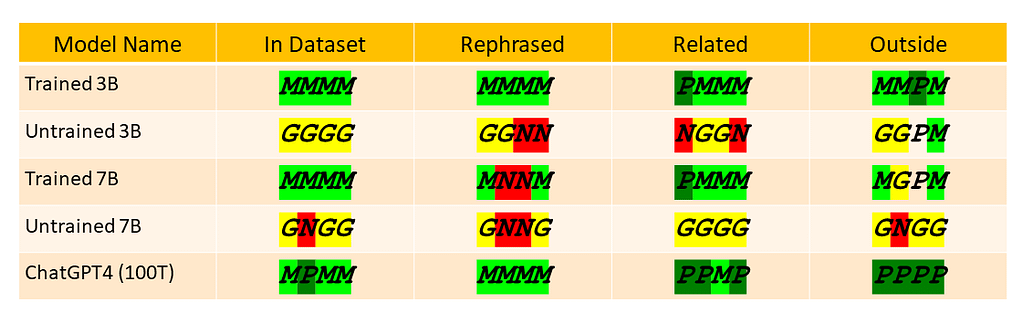
Examining a few of the responses proved quite intriguing. For instance, the answer to “Who was Abu Sa’id Abu’l-Khayr?” included incorrect dates for his lifetime.

The responses to “Who is considered the most significant poet in Persian literature?”, a subjective question, were quite accurate.

I was intrigued to see my model propose Rudaki, a truly remarkable poet in Persian literary history.
Now, let’s see what the models say about me? It’s an excellent example of model hallucinations, and I’m willing to bet a lot went into ChatGPT4 to correct its behavior.

A few key points to summarize the observations:
- Tokenization and text pre-processing are crucial. I noticed several issues with Unicode characters in the text and apostrophes in names.
- The 7B models (both trained and untrained) performed worse. This could be due to errors in the pipeline or potentially an issue with the underlying Bloom model itself. That is, the 7B foundational model might have a flaw that hampers its performance compared to the 3B model.
- Large Language Models (LLMs) can freely hallucinate answers to questions, leading to intriguingly incorrect responses. Addressing this issue could present a significant opportunity.
But it’s not ChatGPT!
I need to acknowledge several crucial criticisms here:
- It’s not a ChatGPT-like model: Correct! Unlike the generative model developed here, ChatGPT is designed for conversations. While an LLM forms the backbone of a conversational model, there’s more to it.
- To fine-tune sophisticated conversational models (like GPT-4), an innovative technique called Reinforcement Learning with Human Feedback (RLHF) is utilized. This involves gathering human feedback (such as rankings) on model outputs and using a secondary model to imitate human preferences. This secondary model is then used to fine-tune the LLM. In our project, we simply employed backpropagation to generate better sequences.
- Machine time wasn’t included in my calculations. The total time I reported was spent coding and interacting with ChatGPT4.
- The learning curve for libraries and tools wasn’t factored into my project timeline. If you’re starting from scratch, getting to grips with these resources could significantly extend your project timeline.
- A genuine real-world question-answering system, especially one that summarizes multiple documents, involves many more steps. For true document summarization, we need to create a vector database, use embedding models to parse sections of documents, and develop a retrieval component. This architecture differs from the current approach of incorporating everything into a single LLM.
It’s not that hard
My intention in this work was to underscore that ChatGPT isn’t some enigmatic sorcery. Despite the seemingly magical outcomes, it’s grounded in well-established techniques accessible to data scientists. Any proficient data scientist with a solid foundation and training in deep learning and generative models can create a similar model.
Junior data scientists may believe that such a task is unattainable or reserved for a select group of highly skilled individuals. I assert it’s not true! Grasp the fundamental concepts, freely leverage the tools and techniques available, and construct your own model.
Optimal use of these foundational models requires more refined methods than the ones I employed here. But if I could accomplish this in 8.5 hours, envision what you could achieve given a proper time commitment.
It’s not that easy
Building a real-world question-answering system is much more challenging than what we’ve done here. I’ve noticed a rush of startups claiming they can create models to aid business operations. However, crafting a customer-facing commercial app that’s ready for real-world use is an entirely different challenge.
- Developing a high-throughput pipeline with low latency requires serious engineering work. The cutting-edge tech in this field includes methods to cut down on inference costs through specialized hardware, optimized model development frameworks, smart modeling techniques, and advanced math concepts.
- Models, by their nature, are based on probabilities. They might not fit every business case, especially if you aim for an error-proof solution.
- Legal and regulatory considerations are very real! The copyright laws around the datasets used can be unclear, and the licensing of the foundational models used by startups could also be doubtful.
- You certainly don’t want to create models that could inadvertently harm your customers, such as using inappropriate language or displaying inappropriate images, especially to minors. Incorporating guardrail models to prevent these unfortunate situations is a major part of the work.
- There are serious security risks associated with these models that aren’t discussed often enough! New hacking techniques are being developed all the time. Regrettably, it’s not in the interest of the big tech companies providing this technology to disclose these risks fully.
- Using these models and technology internally to improve operations might be a more viable option than providing customer-facing apps. The latter is more time-consuming and opens the door to unknown vulnerabilities.
Summary
Utilizing large language models is not sorcery. Every business has the potential to build its own internal tools tailored to its unique use cases and built on its own data. However, this must be done responsibly, with the right precautions.
With the impressive tools and techniques currently available, businesses shouldn’t shy away from developing their own internal models. But, it’s crucial to scope these projects and allocate sufficient resources to them properly. Two common pitfalls are either viewing it as an insurmountable challenge akin to “dark magic” or, on the other hand, underestimating the complexity and assuming it’s too easy. To see my application in action, visit it here: Persian Poets.
Great work! Could a GPT possibly be made in Classical Arabic and knows all about the Islamic contributions during the golden age?
Of course! You need to find the relevant articles, feed it in, and voila! You have a GPT that works on your specific knowledge base.